Publicitate
Sunteți credincios în ideea că, odată ce ceva este publicat pe Internet, este publicat pentru totdeauna? Ei bine, astăzi vom elimina acel mit.
Adevărul este că, în multe cazuri, este foarte posibil să eradicați informațiile de pe Internet. Sigur, există o înregistrare de pagini web care au fost șterse dacă căutați Mașină Wayback, dreapta? Da, absolut. Pe Wayback Machine există înregistrări ale paginilor web care se întorc de mai mulți ani - pagini pe care nu le veți găsi cu o căutare Google, deoarece pagina web nu mai există. Cineva a șters-o sau site-ul a fost închis.
Deci, nu există nicio problemă, nu? Informațiile vor fi întotdeauna gravate în piatra Internetului, acolo pentru generații să le vadă? Ei bine, nu exact.
Adevărul este că, deși ar putea fi dificil sau imposibil să ștergeți știrile majore care au proliferat de la un site de știri sau blog la altul, precum un virus, este de fapt destul de ușor să eradicați complet o pagină web sau mai multe pagini web din toate înregistrările existenței - pentru a elimina pagina respectivă atât pentru motoarele de căutare, cât și pentru
Mașină Wayback Noua mașină Wayback vă permite să călătoriți vizual în timp pe InternetSe pare că, de la lansarea Wayback Machine în 2001, proprietarii site-ului au decis să arunce back-end-ul bazat pe Alexa și să-l reproiecteze cu propriul cod open source. După efectuarea testelor cu ... Citeste mai mult . Desigur, există o captură, dar vom ajunge la asta.3 Moduri de a elimina paginile de blog de pe net
Prima metodă este cea pe care o folosesc majoritatea proprietarilor de site-uri web, pentru că nu știu mai bine - ștergând pur și simplu paginile web. Acest lucru se poate întâmpla deoarece v-ați dat seama că aveți conținut duplicat pe site-ul dvs. sau pentru că aveți o pagină pe care nu doriți să o afișați în rezultatele căutării.
Pur și simplu ștergeți pagina
Problema cu ștergerea completă a paginilor de pe site-ul dvs. web este că, deoarece deja ați stabilit pagina pe pagina net, este posibil să existe link-uri de pe propriul site, precum și link-uri externe de la alte site-uri către acel anume pagină. Când o ștergeți, Google recunoaște imediat pagina dvs. ca fiind o pagină care lipsește.
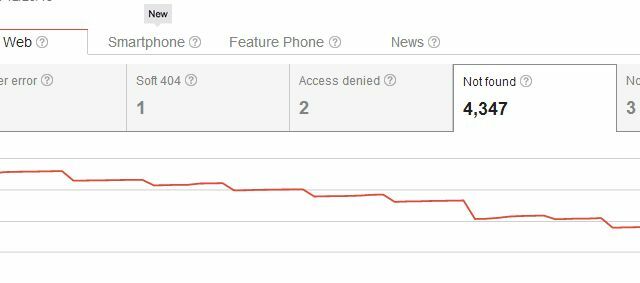
Așadar, la ștergerea paginii dvs. nu ați creat doar o problemă cu erori de crawliere „Nu s-au găsit”, ci ați creat o problemă pentru oricine s-a conectat vreodată la pagină. De obicei, utilizatorii care ajung pe site-ul dvs. de pe unul dintre aceste link-uri externe vor vedea pagina dvs. 404, care nu este problemă majoră, dacă utilizați ceva precum codul 404 personalizat al Google pentru a oferi utilizatorilor sugestii utile sau alternative. Dar, credeți că ar putea exista modalități mai grațioase de a șterge paginile din rezultatele căutării fără a da drumul tuturor celor 404 pentru link-urile existente, nu?
Ei bine, există.
Ștergeți o pagină din rezultatele căutării Google
În primul rând, ar trebui să înțelegeți că dacă pagina web pe care doriți să o eliminați din rezultatele căutării Google nu este o pagină din propriul dvs. site, atunci nu aveți noroc dacă nu există motive legale sau dacă site-ul a postat informațiile personale online fără dvs. permisiune. Dacă acesta este cazul, atunci utilizați Google eliminarea depanatorului pentru a trimite o solicitare pentru a elimina pagina din rezultatele căutării. Dacă aveți un caz valid, este posibil să găsiți un anumit succes eliminând pagina - desigur s-ar putea să aveți un succes și mai mare contactarea proprietarului site-ului web Cum să eliminați informațiile personale false de pe InternetConfidențialitatea online nu mai este garantată. Aflați cum să raportați un site web și să eliminați informațiile personale de pe internet. Citeste mai mult așa cum am descris cum să fac înapoi în 2009.
Acum, dacă pagina pe care doriți să o eliminați din rezultatele căutării este pe site-ul dvs., aveți noroc. Tot ce trebuie să faci este să creezi un robots.txt fișieră și asigurați-vă că nu ați fost permisă fie pagina specifică pe care nu o doriți în rezultatele căutării, fie întregul director cu conținutul pe care nu îl doriți indexat. Iată cum arată blocarea unei singure pagini.
Agent utilizator: * Renunță: /my-deleted-article-that-i-want-removed.html
Puteți bloca roboții de la crawling directoare întregi ale site-ului dvs. după cum urmează.
Agent utilizator: * Renunță: / content-about-personal-stuff /
Google are un excelent pagina de asistență care vă poate ajuta să creați un fișier robots.txt dacă nu ați mai creat unul înainte. Acest lucru funcționează extrem de bine, așa cum am explicat recent într-un articol despre structurarea tranzacțiilor de sindicalizare Cum să negociați ofertele de sindicalizare și să vă protejați clasamentele de căutareSindicalizarea este toată ravagia în aceste zile. Dar dintr-o dată puteți afla că partenerul de sindicalizare este listat mai mare decât dvs. în rezultatele căutării pentru o poveste pe care ați scris-o inițial! Protejați-vă clasamentele de căutare. Citeste mai mult astfel încât să nu vă facă rău (cereți partenerilor de sindicalizare să nu permită indexarea paginilor lor unde sunteți sindicalizat). Odată ce propriul meu partener de sindicalizare a fost de acord să facă acest lucru, paginile cu conținut duplicat de pe blogul meu au dispărut complet din listările de căutare.
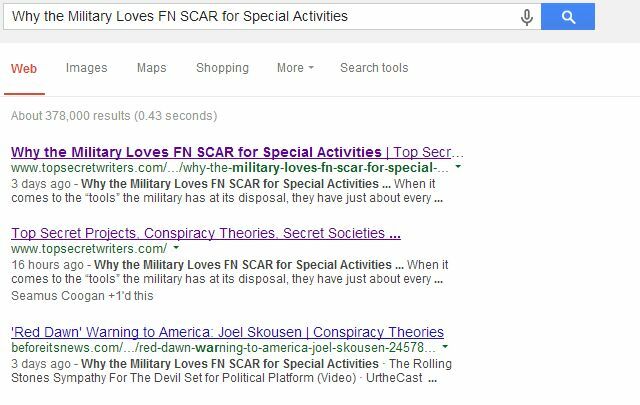
Doar site-ul principal apare pe locul al treilea pentru pagina în care sunt listate titlul nostru, dar blogul meu este acum listat atât la primul și la al doilea spot; ceva ce ar fi fost aproape imposibil dacă un site web cu autorități superioare lăsase indexată pagina duplicată.
Ceea ce mulți nu își dau seama este că acest lucru este posibil să se realizeze și cu Internet Archive (Wayback Machine). Iată liniile pe care trebuie să le adăugați la fișierul dvs. robots.txt pentru a face acest lucru.
User-agent: ia_archiver. Renunțare: / eșantion-categorie /
În acest exemplu, îi spun Internet Archive să elimine orice lucru din subdirectorul pentru categorii de probe de pe site-ul meu de la Wayback Machine. Arhiva Internet explică cum se face acest lucru pe pagina lor de ajutor pentru excludere. De asemenea, aceștia explică faptul că „Arhiva Internet nu este interesată să ofere acces la site-uri web sau la alte documente de internet ai căror autori nu își doresc materialele din colecție.”
Acest lucru contravine credinței obișnuite că orice este postat pe Internet este aruncat în arhivă pentru toată eternitatea. Nope - webmasterii care dețin conținutul pot elimina în mod specific conținutul din arhivă folosind abordarea robots.txt.
Eliminați o pagină individuală cu etichete Meta
Dacă aveți doar câteva pagini individuale pe care doriți să le eliminați din rezultatele Căutării Google, nu trebuie să utilizați de fapt robotul.txt în orice caz, puteți adăuga pur și simplu meta tag-ul „roboți” corect în paginile individuale și să le spuneți roboților să nu indexeze sau să nu urmeze link-urile pe întregul pagină.

Puteți utiliza meta "roboții" de mai sus pentru a opri roboții de la indexarea paginii sau puteți spune în mod special robotului Google să nu indexeze, astfel încât pagina să fie eliminată doar din rezultatele căutării Google, iar alți roboți de căutare ar putea accesa în continuare pagina conţinut.
Depinde complet de modul în care doriți să gestionați ce fac roboții cu pagina și dacă pagina este listată sau nu. Pentru doar câteva pagini individuale, aceasta poate fi o abordare mai bună. Pentru a elimina un întreg director de conținut, mergeți cu metoda robots.txt.
Ideea de a „elimina” conținutul
Acest fel de transformă întreaga noțiune de „ștergerea conținutului de pe Internet” pe capul său. Tehnic, dacă eliminați toate linkurile proprii către o pagină de pe site-ul dvs. și o eliminați din Căutarea Google și din Internet Archive folosind tehnica robots.txt, pagina este destinată tuturor intențiilor și scopurilor „șterse” de pe Internet. Lucrul cel mai interesant este însă că, dacă există link-uri la pagină, aceste link-uri vor funcționa în continuare și nu veți declanșa 404 erori pentru acei vizitatori.
Este o abordare mai „blândă” de a elimina conținutul de pe Internet fără a încuraja în întregime popularitatea link-ului existent pe site-ul dvs. pe Internet. În cele din urmă, modul în care gestionați ce conținut este colectat de către motoarele de căutare și de la Internet Archive depinde de dvs., dar întotdeauna Amintiți-vă că, în ciuda a ceea ce spun oamenii despre durata de viață a lucrurilor care sunt postate online, acesta este într-adevăr complet în interiorul dvs. Control.
Ryan are o diplomă de licență în inginerie electrică. A lucrat 13 ani în domeniul ingineriei automatizării, 5 ani la IT, iar acum este inginer pentru aplicații. Fost redactor manager al MakeUseOf, a vorbit la conferințele naționale despre vizualizarea datelor și a fost prezentat la TV și radio naționale.