Publicitate
Web Crawling este extrem de util pentru a automatiza anumite sarcini efectuate de rutină pe site-uri web. Puteți scrie un crawler pentru a interacționa cu un site web, așa cum ar face un om.
În un articol anterior Cum să construiți un crawler web de bază pentru a extrage informații de pe un site webAți dorit vreodată să capturați informații de pe un site web? Iată cum să scrieți un crawler pentru a naviga pe un site web și a extrage ceea ce aveți nevoie. Citeste mai mult , am acoperit elementele de bază ale scrierii a webcrawler Ce este Web Scraping? Cum să colectați date de pe site-uri webV-ați văzut vreodată că pierzi timp prețios citind date de pe paginile web? Iată cum să găsiți datele pe care le doriți cu web scraping. Citeste mai mult folosind modulul python, scrapy. Limitarea acestei abordări este că crawler-ul nu acceptă javascript. Nu va funcționa corect cu acele site-uri web care folosesc în mod intens javascript pentru a gestiona interfața cu utilizatorul. Pentru astfel de situații, puteți scrie un crawler care utilizează Google Chrome și, prin urmare, poate gestiona javascript la fel ca un browser Chrome normal, condus de utilizator.
Automatizarea Google Chrome implică utilizarea unui instrument numit Seleniu. Este o componentă software care se află între programul dvs. și browser și vă ajută să conduceți browserul prin program. În acest articol, vă prezentăm procesul complet de automatizare a Google Chrome. Pașii includ în general:
- Configurarea seleniului
- Utilizarea Google Chrome Inspector pentru a identifica secțiunile paginii web
- Scrierea unui program java pentru automatizarea Google Chrome
În scopul articolului, să investigăm cum să citim Google Mail din java. Deși Google oferă un API (Interfață de programare a aplicației) pentru a citi e-mailurile, în acest articol folosim Selenium pentru a interacționa cu Google Mail pentru a demonstra procesul. Google Mail folosește în mare măsură javascript și, prin urmare, este un bun candidat pentru a învăța Selenium.
Configurarea seleniului
Driver web
După cum sa explicat mai sus, Seleniu constă dintr-o componentă software care rulează ca un proces separat și efectuează acțiuni în numele programului java. Această componentă se numește Driver web și trebuie descărcat pe computer.
Click aici pentru a accesa site-ul de descărcare Selenium, faceți clic pe cea mai recentă versiune și descărcați fișierul corespunzător pentru sistemul de operare al computerului dvs. (Windows, Linux sau MacOS). Este o arhivă ZIP care conține chromedriver.exe. Extrageți-l într-o locație potrivită, cum ar fi C:\WebDrivers\chromedriver.exe. Vom folosi această locație mai târziu în programul java.
Module Java
Următorul pas este să configurați modulele java necesare pentru a utiliza Selenium. Presupunând că utilizați Maven pentru a construi programul java, adăugați următoarea dependență la dvs POM.xml.
org.seleniumhq.selenium seleniu-java 3.8.1 Când rulați procesul de construire, toate modulele necesare ar trebui să fie descărcate și configurate pe computer.
Primii pași cu seleniu
Să începem cu seleniul. Primul pas este crearea unui ChromeDriver instanță:
Driver WebDriver = nou ChromeDriver(); Ar trebui să deschidă o fereastră Google Chrome. Să navigăm la pagina de căutare Google.
driver.get(" http://www.google.com"); Obțineți o referință la elementul de introducere a textului, astfel încât să putem efectua o căutare. Elementul de introducere a textului are numele q. Localizăm elemente HTML pe pagină folosind metoda WebDriver.findElement().
Element WebElement = driver.findElement (By.name("q")); Puteți trimite text către orice element folosind metoda sendKeys(). Să trimitem un termen de căutare și să-l încheiem cu o nouă linie, astfel încât căutarea să înceapă imediat.
element.sendKeys("terminator\n"); Acum că o căutare este în curs, trebuie să așteptăm pagina cu rezultate. Putem face asta după cum urmează:
nou WebDriverWait (driver, 10) .until (d -> d.getTitle().toLowerCase().startsWith("terminator")); Acest cod îi spune practic lui Selenium să aștepte 10 secunde și să revină când începe titlul paginii terminator. Folosim o funcție lambda pentru a specifica condiția de așteptat.
Acum putem obține titlul paginii.
System.out.println("Titlu: " + driver.getTitle()); Odată ce ați terminat cu sesiunea, fereastra browserului poate fi închisă cu:
driver.quit(); Și asta, oameni buni, este o simplă sesiune de browser controlată folosind java prin seleniu. Pare destul de simplu, dar vă permite să programați o mulțime de lucruri pe care în mod normal ar trebui să le faceți manual.
Folosind Google Chrome Inspector
Google Chrome Inspector Descoperiți problemele site-ului cu instrumentele pentru dezvoltatori Chrome sau FirebugDacă ați urmat până acum tutorialele mele jQuery, este posibil să fi întâlnit deja unele probleme de cod și să nu știți cum să le remediați. Când te confrunți cu un fragment de cod nefuncțional, este foarte... Citeste mai mult este un instrument de neprețuit pentru a identifica elementele care trebuie utilizate cu seleniu. Ne permite să țintim elementul exact din java pentru extragerea de informații, precum și o acțiune interactivă, cum ar fi clic pe un buton. Iată o instrucțiune despre cum să utilizați Inspector.
Deschideți Google Chrome și navigați la o pagină, spuneți pagina IMDb pentru Liga Justiției (2017).
Să găsim elementul pe care vrem să-l țintem, să spunem rezumatul filmului. Faceți clic dreapta pe rezumat și selectați „Inspectați” din meniul pop-up.

Din fila „Elemente”, putem vedea că textul rezumat este a div cu o clasă de text_rezumat.
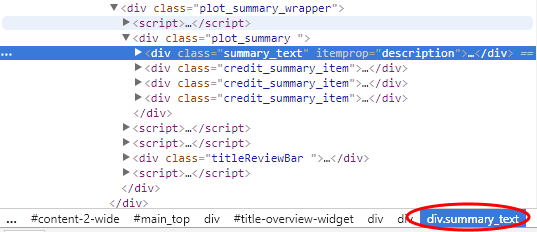
Folosind CSS sau XPath pentru selecție
Selenium acceptă selectarea elementelor din pagină folosind CSS. (Dialectul CSS acceptat este CSS2). De exemplu, pentru a selecta textul rezumat din pagina IMDb de mai sus, am scrie:
WebElement summaryEl = driver.findElement (By.cssSelector("div.summary_text")); De asemenea, puteți utiliza XPath pentru a selecta elemente într-un mod foarte similar (Go Aici pentru specificatii). Din nou, pentru a selecta textul rezumat, am face:
WebElement summaryEl = driver.findElement (By.xpath("//div[@class='summary_text']")); XPath și CSS au capacități similare, astfel încât să puteți utiliza oricare cu care vă simțiți confortabil.
Citirea Google Mail din Java
Să ne uităm acum la un exemplu mai complex: preluarea Google Mail.
Porniți driverul Chrome, navigați la gmail.com și așteptați până când pagina este încărcată.
Driver WebDriver = nou ChromeDriver(); driver.get(" https://gmail.com"); nou WebDriverWait (driver, 10) .until (d -> d.getTitle().toLowerCase().startsWith("gmail")); Apoi, căutați câmpul de e-mail (este numit cu id identificatorId) și introduceți adresa de e-mail. Apasă pe Următorul butonul și așteptați să se încarce pagina parolei.
/* Introduceți numele de utilizator/e-mailul */ { driver.findElement (By.cssSelector("#identifierId")).sendKeys (email); driver.findElement (By.cssSelector(".RveJvd")).click(); } WebDriverWait nou (driver, 10) .până la (d ->! d.findElements (By.xpath("//div[@id='parola']")).isEmpty() );Acum, introducem parola, facem clic pe Următorul butonul din nou și așteptați ca pagina Gmail să se încarce.
/* Introdu parola */ { driver .findElement (By.xpath("//div[@id='parola']//input[@type='parola']")) .sendKeys (parola); driver.findElement (By.cssSelector(".RveJvd")).click(); } WebDriverWait nou (driver, 10) .până la (d ->! d.findElements (By.xpath("//div[@class='Cp']")).isEmpty() );Preluați lista de rânduri de e-mail și treceți în buclă peste fiecare intrare.
Listărows = driver .findElements (By.xpath("//div[@class='Cp']//table/tbody/tr")); pentru (WebElement tr: rows) { } Pentru fiecare intrare, preluați Din camp. Rețineți că unele intrări Din ar putea avea mai multe elemente în funcție de numărul de persoane din conversație.
{ /* Din elementul */ System.out.println("De la: "); pentru (WebElement e: tr .findElements (By.xpath(".//div[@class='yW']/*"))) { System.out.println(" " + e.getAttribute("e-mail") + ", " + e.getAttribute("nume") + ", " + e.getText()); } }Acum, adu subiectul.
{ /* Subiect */ System.out.println("Sub: " + tr.findElement (By.xpath(".//div[@class='yNN']")).getText()); }
Și data și ora mesajului.
{ /* Data/Ora */ WebElement dt = tr.findElement (By.xpath("./td[8]/*")); System.out.println("Data: " + dt.getAttribute("titlu") + ", " + dt.getText()); }
Iată numărul total de rânduri de e-mail din pagină.
System.out.println (rows.size() + " mail-uri."); Și, în sfârșit, am terminat, așa că ieșim din browser.
driver.quit(); Pentru a recapitula, puteți folosi Selenium cu Google Chrome pentru a accesa cu crawlere acele site-uri web care folosesc javascript în mod intens. Și cu Google Chrome Inspector, este destul de ușor să elaborezi CSS-ul sau XPath-ul necesar pentru extragerea sau interacțiunea cu un element.
Aveți proiecte care beneficiază de utilizarea seleniului? Și cu ce probleme te confrunți cu ea? Vă rugăm să descrieți în comentariile de mai jos.


